

 |
| KAIST 전기및전자공학부 박진우 박사, 조승근 석사과정, 한동수 교수. KAIST 제공 |
KAIST 전기및전자공학부 한동수 연구팀은 데이터센터 밖 소비자급 GPU를 활용해 대규모 언어모델(LLM) 인프라 비용을 크게 낮출 수 있는 '스펙엣지'(SpecEdge)를 개발했다고 28일 밝혔다.
LLM 기반 AI 서비스는 대부분 고가의 데이터센터 GPU에 의존했다. 이로 인해 서비스 운영 비용이 높고 AI 기술 활용 진입장벽도 컸다. 스펙엣지는 데이터센터 GPU와 개인 PC나 소형 서버에 탑재된 엣지 GPU가 역할을 나눠 LLM 추론 인프라를 함께 구성하는 방식이다. 이 기술을 적용했을 때 기존 데이터센터 GPU만 사용하는 방식에 비해 AI가 문장을 만들어내는 최소 단위인 토큰당 비용을 67.6% 절감하는 것으로 나타났다.
연구팀은 '추측적 디코닝'(Speculative Decoding)이라는 방법을 활용했다. 엣지 GPU에 배치된 소형 언어모델이 확률이 높은 토큰 시퀀스를 빠르게 생성하면 데이터센터의 대규모 언어모델이 이를 일괄 검증하는 방식이다. 엣지 GPU는 서버의 응답을 기다리지 않고 계속 단어를 만들어 LLM 추론 속도와 인프라 효율을 동시에 높일 수 있다.
데이터센터 GPU에서만 추측적 디코딩을 수행하는 방식과 비교했을 때 비용 효율성은 1.91배, 서버 처리량은 2.22배 향상됐다. 일반적인 인터넷 속도에서도 문제없이 작동해 별도 특수한 네트워크 환경 없이도 적용할 수 있는 것을 확인했다.
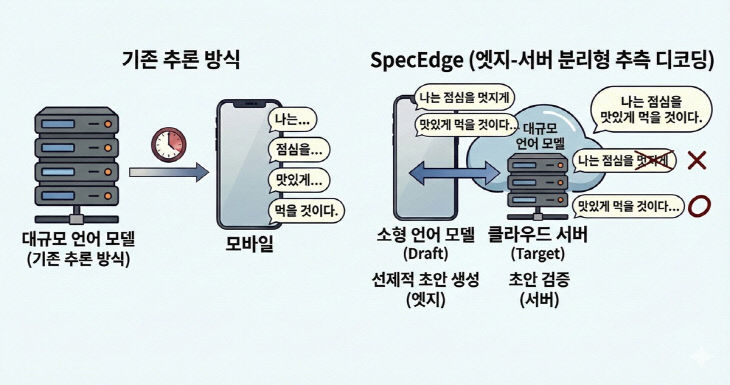 |
| 연구팀이 개발한 SpecEdge의 기존과 비교 개념도 |
한동수 KAIST 교수는 "데이터센터를 넘어 사용자 주변에 있는 엣지 자원까지 LLM 인프라로 활용하는 것이 목표"라며 "이를 통해 AI 서비스 제공 비용을 낮추고 누구나 고품질의 AI를 활용할 수 있는 환경을 만들고자 한다"고 말했다.
이번 연구는 KAIST 박진우 박사와 조승근 석사과정이 함께했으며 정보통신기획평가원(IITP) 과제 지원을 받았다. 임효인 기자
중도일보(www.joongdo.co.kr), 무단전재 및 수집, 재배포 금지





